| Autore |
Discussione |
|
|
serbring
Utente Junior


486 Messaggi |
 Inserito il - 14 luglio 2009 : 13:51:53 Inserito il - 14 luglio 2009 : 13:51:53




|
|
Ho fatto delle misure (non posso spiegarvi di cosa), comunque la dispersione � "elevata" graficamente , ma riesco ad avere una retta di regressione buona con un r^2 corretto dello 0.9. Siccome ho fatto molte prove per avere una regressione buona, � possibile togliere i dati meno influenti cos� da avere dei grafici migliori (con meno dati ed una ridotta dispesione) senza alterare in modo significativo la retta di regressione trovata? Posso raggiungere questo scopo eliminando i dati i cui residui standardizzati sono al di fuori della banda di confidenza?
|
|
|
|
|
chick80
Moderatore


Citt�: Edinburgh
11491 Messaggi |
Inserito il - 15 luglio 2009 : 08:11:33
|
| Se non hai ragioni pratiche per eliminare quei dati (es. qualcosa che � andato storto mentre li misuravi) non toglierli. Pensa piuttosto a perch� hai un'alta dispersione. Inoltre hai ragionato sul fatto che magari le due variabili non sono linearmente correlate? |
Sei un nuovo arrivato?
Leggi il regolamento del forum e presentati qui
My photo portfolio (now on G+!) |
 |
|
|
dallolio_gm
Moderatore

Prov.: Bo!
Citt�: Barcelona/Bologna
2445 Messaggi |
Inserito il - 15 luglio 2009 : 10:25:04

|
| Potresti aggiustare il valore di alpha, in modo da rendere semi-trasparenti i valori distaccati. |
Il mio blog di bioinformatics (inglese): BioinfoBlog
Sono un po' lento a rispondere, posso tardare anche qualche giorno... ma abbiate fede! :-) |
|
|
|
serbring
Utente Junior
486 Messaggi |
Inserito il - 15 luglio 2009 : 10:55:40
|
Citazione:
Messaggio inserito da dallolio_gm
Potresti aggiustare il valore di alpha, in modo da rendere semi-trasparenti i valori distaccati.
Cio� in che modo? |
|
|
|
serbring
Utente Junior
486 Messaggi |
Inserito il - 15 luglio 2009 : 10:57:27
|
Citazione:
Messaggio inserito da chick80
Se non hai ragioni pratiche per eliminare quei dati (es. qualcosa che � andato storto mentre li misuravi) non toglierli. Pensa piuttosto a perch� hai un'alta dispersione. Inoltre hai ragionato sul fatto che magari le due variabili non sono linearmente correlate?
diciamo che nel fare la misura c'era molto "rumore" a causa del situazione particolare in cui si trovava a misurare lo strumento |
|
|
|
chick80
Moderatore
Citt�: Edinburgh
11491 Messaggi |
Inserito il - 15 luglio 2009 : 13:24:09
|
| Beh, allora non ci puoi fare nulla. Personalmente preferisco lasciare tutti i dati e motivarne la dispersione piuttosto che arbitrariamente cancellarne alcuni in quanto "brutti". |
Sei un nuovo arrivato?
Leggi il regolamento del forum e presentati qui
My photo portfolio (now on G+!) |
|
|
|
serbring
Utente Junior
486 Messaggi |
Inserito il - 15 luglio 2009 : 15:47:11
|
| no pensavo che ci fosse un modo per cancellare i punti in base alla distrubuzione di probabilit�, ad esempio: il l'80% dei punti si trova in una certa zona e quindi si potrebbe cancellare il restante 20%. Non s� se mi sono spiegato bene. |
|
|
|
TMax
Utente Junior

Prov.: BG
Citt�: Capriate
270 Messaggi |
Inserito il - 15 luglio 2009 : 18:14:34
|
scusa se hai una sovradispersione forse si tratta di una condizione da trattare in modo specifico
con ad esempio l'uso di regressione di Poisson o regressione binomiale negativa.
non cercherei di piegare i dati alle aspettative:-)
per� non conoscendo la natura dei dati non posso capire bene il tipo di problema o cosa intendi tu per sovradispersione.
ciao
TMax |
|
|
|
serbring
Utente Junior
486 Messaggi |
Inserito il - 16 luglio 2009 : 13:06:18
|
| no non voglio assolutamente piegare i dati alle aspettative, avendo fatto molte prove ed avendo una dispersione elevata, comunque un trend � ben visibile anche ad occhio nudo, ma essendoci una certa dispersione, l'R^2 corretto non'� altissimo (0.6). Volevo solo eliminare i dati "anomali" cio� dati che probabilisticamente sono meno importanti rispetto ad altri. Io conosco solo la regressione lineare, non sapevo che esistessero altri tipi di regressioni. Prover� a vedere queste altre due tipologie di regressioni |
|
|
|
chick80
Moderatore
Citt�: Edinburgh
11491 Messaggi |
Inserito il - 16 luglio 2009 : 14:16:14
|
Per regressione si intende una tecnica che ti permette di mettere in relazione una variabile dipendente ad una o pi� variabili dipendenti.
Se la relazione fra le due � lineare allora si pu� fare una regressione lineare, ad es. con il metodo dei minimi quadrati (ma non � il solo metodo esistente).
La relazione non � per� necessariamente lineare: le due variabili possono ad es. essere in una relazione logaritmica o quadratica o una qualsiasi relazione.
Prendi un caso tipicamente "biochimico": la velocit� di una reazione enzimatica in funzione della concentrazione di substrato.
Le due variabili (velocit� e concentrazione) sono correlata, ma non in modo lineare, bens� in modo iperbolico (secondo la legge di Michaelis-Menten).
In questo caso se tu vai a misurare la velocit� in funzione della concentrazione puoi poi "modellare" un'iperbole tramite un opportuno metodo di regressione. |
Sei un nuovo arrivato?
Leggi il regolamento del forum e presentati qui
My photo portfolio (now on G+!) |
|
|
|
serbring
Utente Junior
486 Messaggi |
Inserito il - 17 luglio 2009 : 15:04:08
|
s� quelle cose le sapevo, ero solo interessato a sapere se c'era ed in quale modo vanno trattati i dati con una certa dispersione. Ho visto letto in rete che se la varianza non � almeno 3 volte la grandezza delle veariabili misurati allora la misura non'� buona. Nel mio caso la varianza � circa 1/20 dei valori da me misurati, quindi non credo di poter dire che la misura fatta � pessima.
|
|
|
|
serbring
Utente Junior
486 Messaggi |
Inserito il - 20 luglio 2009 : 11:54:16
|
una domanda, come posso con R fare una regressione con un modello delle equazione scelto da me?
Il modello in questione � il seguente:
y=D*sin(c*atan(b*x-e*(b*x-atan(b*x))))
|
|
|
|
chick80
Moderatore
Citt�: Edinburgh
11491 Messaggi |
Inserito il - 20 luglio 2009 : 22:17:44
|
Allora, lo puoi fare in vari modi.
Due metodi sono la Least Square Extimation (LSE), che � essenzialmente il metodo dei minimi quadrati e la Maximum Likelihood Extimation (MLE).
In entrambi i casi dovrai partire da un set di parametri iniziali (nel tuo caso D, c, b, ed e) che poi verranno ottimizzati per trovare il fit migliore.
Nel caso della LSE vai a minimizzare la somma dei quadrati dei residui, nella MLE vai a massimizzare L(D,c,b,e|y), cio� la likelihood che il modello con quei parametri rappresenti effettivamente i tuoi dati sperimentali y.
Ti consiglio questo articolo a riguardo: Tutorial on maximum likelihood extimation - Myung - Journal of Mathematical Psychology 47 (2003) 90�100
In generale, per motivi che -ti dico la verit�- non mi sono chiarissimi (anzi, se qualcuno avesse la bont� di spiegarmeli...), i matematici preferiscono la MLE alla LSE.
---
Detto questo, in R ci sono molti modi di fare un fit. Puoi fare un fit tramite LSE usando nls (nonlinear least squares), mentre per la MLE puoi usare ad es. la funzione mle del package stats4 (ma si pu� anche fare in altri modi).
LSE:
# Innanzitutto creiamo una funzione del tuo modello
myModel = function(x,D,c,b,e)
{
D*sin(c*atan(b*x-e*(b*x-atan(b*x))))
}
# qui dovresti caricare i tuoi dati.
# Io metto dei dati fittizi che genero secondo il tuo modello
x = 1:100
y = myModel(x, 5, 0.35, 0.22, 4)
# aggiungo un po' di "rumore" per non avere dei punti "perfetti"
y = y + 0.25*rnorm(100)
# chiamiamo nls
# la funzione richiede dei parametri iniziali. Io ovviamente qui
# so gi� il risultato... quindi � facile sceglierli!!!
# In una situazione reale devi avere un qualche metodo di trovare dei
# buoni parametri iniziali, che approssimino bene la soluzione.
#model = nls(y~myModel(x,D,c,b,e), start=list("D"=3.5, "c"=0.5, "b"=0.4, "e"=2))
res = coef(model)
print(res)
# Disegnamo i nostri punti sperimentali
plot(x, y, pch=20, col="gray")
# La curva teorica
points(x, myModel(x, 5, 0.35, 0.22, 4), "l", col="blue", lwd=1)
# E il fitting
points(x, myModel(x, res[1], res[2], res[3], res[4]), "l", col="red", lwd=2)
Questo codice ti dar� dei risultati tipo (cambiano ogni volta perch� la componente di rumore � variabile)
D c b e
2.7267419 0.7733281 0.1576721 5.4495819
che, pur non essendo esattamente quelli teorici (sulla base dei quali ho generato i miei dati) danno un buon fit. La curva rossa � il fit ottenuto con nls, la blu � la curva teorica.
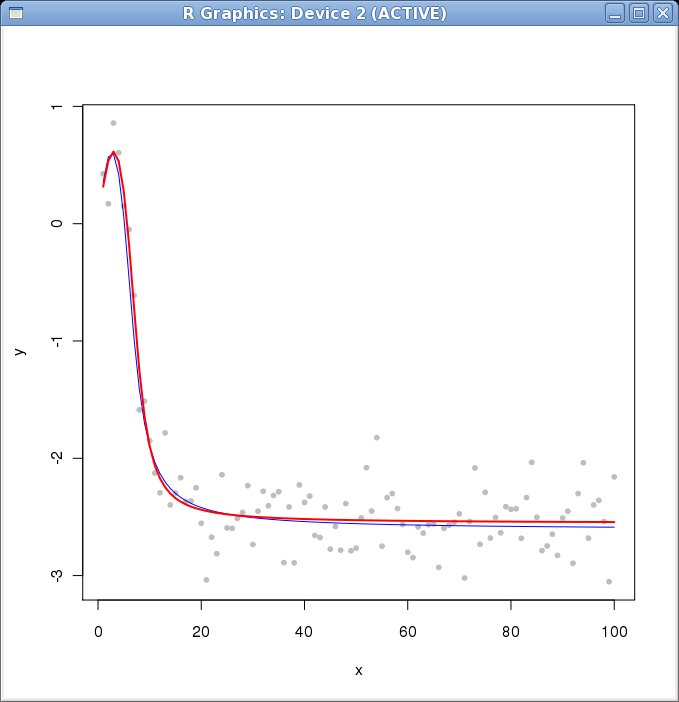
===
MLE
Ho provato a mettere gi� una funzione per questa ma mi d� sempre errore... probabilmente sbaglio qualcosa nella funzione di log-likelihood... magari qualcun altro pi� esperto sapr� chiarirci le idee.
Giusto per, ti aggiungo il codice (che per� non funziona!)
# generi i dati come sopra
# definiamo una funzione che calcola la likelihood per il tuo modello.
# Vedi http://www.weibull.com/hotwire/issue33/relbasics33.htm per una breve
# spiegazione di come ottenere questa funzione... evidentemente c'� un errore qui
likFunct = function(D, c, b, e)
{
-log(sum(myModel(x, D,c,b,e)))
}
# chiamiamo mle.
model = mle(likFunct, start=list("D"=5.1, "c"=0.3, "b"=0.2, "e"=4.1))
res = coef(model)
print(res)
|
Sei un nuovo arrivato?
Leggi il regolamento del forum e presentati qui
My photo portfolio (now on G+!) |
|
|
|
serbring
Utente Junior
486 Messaggi |
Inserito il - 23 luglio 2009 : 15:46:48
|
| perfetto grazie chick, adesso lo provo subito. Un ultima domanda, ma se io non conoscessi il modello matematico tra una variabile x ed una y, qual'� la tipologia di regressione che mi massimizza l'r^2? La rete neurale � la migliore? |
|
|
|
chick80
Moderatore
Citt�: Edinburgh
11491 Messaggi |
Inserito il - 23 luglio 2009 : 18:17:38
|
Allora, bisogna innanzitutto dire che NON � detto che avendo due modelli uno con R2 = 0.95 e uno con R2=0.76 il primo sia meglio del secondo.
I tuoi dati sperimentali derivano da un certo processo che tu cerchi di modellare con un'espressione matematica. Probabilmente non troverai mai la VERA espressione matematica che genera quei dati, ma ti ci puoi avvicinare (infatti stai costruendo un *modello*).
Non sono cos� tanto esperto a riguardo e non ho mai usato reti neurali per questi scopi, quindi non so dirti se sia o meno una buona idea utilizzarle. Forse per� la cosa potrebbe diventare un po' "ipotetica", non credi? Cio�, se non hai almeno un'idea di quale sia il processo alla base di ci� che stai misurando allora non avrai comunque modo di confermare il risultato che ti sputa fuori la rete neurale...
Credo che altri metodi da considerare prima di buttarsi nelle reti neurali siano la regressione locale (LOESS) o lo spline-fitting.
Poi ad ogni modo il tutto dipende da cosa ci vuoi fare con questo modello, da che tipo di dati stai analizzando etc etc
PS: ho visto alcuni lavori in cui per comparare diversi modelli utilizzano il test di Kolmogorov-Smirnov, scegliendo come migliore quello con la p maggiore. Tuttavia anche negli stessi articoli che fanno uso di questo tipo di test dicono che la cosa � abbastanza arbitraria... (e non so quanto sia statisticamente corretta) |
Sei un nuovo arrivato?
Leggi il regolamento del forum e presentati qui
My photo portfolio (now on G+!) |
|
|
|
serbring
Utente Junior
486 Messaggi |
Inserito il - 24 luglio 2009 : 14:21:35
|
Citazione:
Messaggio inserito da chick80
Allora, bisogna innanzitutto dire che NON � detto che avendo due modelli uno con R2 = 0.95 e uno con R2=0.76 il primo sia meglio del secondo.
I tuoi dati sperimentali derivano da un certo processo che tu cerchi di modellare con un'espressione matematica. Probabilmente non troverai mai la VERA espressione matematica che genera quei dati, ma ti ci puoi avvicinare (infatti stai costruendo un *modello*).
Non sono cos� tanto esperto a riguardo e non ho mai usato reti neurali per questi scopi, quindi non so dirti se sia o meno una buona idea utilizzarle. Forse per� la cosa potrebbe diventare un po' "ipotetica", non credi? Cio�, se non hai almeno un'idea di quale sia il processo alla base di ci� che stai misurando allora non avrai comunque modo di confermare il risultato che ti sputa fuori la rete neurale...
Credo che altri metodi da considerare prima di buttarsi nelle reti neurali siano la regressione locale (LOESS) o lo spline-fitting.
Poi ad ogni modo il tutto dipende da cosa ci vuoi fare con questo modello, da che tipo di dati stai analizzando etc etc
PS: ho visto alcuni lavori in cui per comparare diversi modelli utilizzano il test di Kolmogorov-Smirnov, scegliendo come migliore quello con la p maggiore. Tuttavia anche negli stessi articoli che fanno uso di questo tipo di test dicono che la cosa � abbastanza arbitraria... (e non so quanto sia statisticamente corretta)
sto guardando qualcosa sulla regressione spline. Son riuscito ad ottenere qualcosa di meglio. |
|
|
|
serbring
Utente Junior
486 Messaggi |
Inserito il - 24 luglio 2009 : 17:20:10
|
| ravanando in qualche libro ho trovato che il modello � inizialmente lineare, ed infatti guardando la disposizione dei punti sembrerebbe esserlo, successivamente diventa non lineare perch� entra in gioco dei fattori secondari che complicano un casino la situazione. Sarebbe interessante qunatificare fino a che fino a quale valore della x posso dire che il mio modello � lineare. c'� un modo per scoprilo? Potrei imporre che la spline nel primo tratto sia lineare? E' possibile? |
|
|
|
chick80
Moderatore
Citt�: Edinburgh
11491 Messaggi |
Inserito il - 25 luglio 2009 : 11:39:30
|
Hmmmm.... guarda non ho mai giocato troppo con le splines, ma in ufficio ho un paio di libri che forse potrebbero essere utili.
Dovrei passare oggi pomeriggio o domani mattina, guardo e ti faccio sapere se trovo qualcosa.
 |
Sei un nuovo arrivato?
Leggi il regolamento del forum e presentati qui
My photo portfolio (now on G+!) |
|
|
|
serbring
Utente Junior
486 Messaggi |
Inserito il - 26 luglio 2009 : 10:26:33
|
Citazione:
Messaggio inserito da chick80
Hmmmm.... guarda non ho mai giocato troppo con le splines, ma in ufficio ho un paio di libri che forse potrebbero essere utili.
Dovrei passare oggi pomeriggio o domani mattina, guardo e ti faccio sapere se trovo qualcosa.
ciao Chick ho risolto,
si deve usare il comando RCS contenuto nel pacchetto design, solamente che gli devo dare io il valore oltre il quale l'andamento � lineare e pertanto mi toccher� fare un po' di prove, od in alternativa fare un ciclo for che mi f� variare il punto in cui verr� persa la linearit� e prendere la regressione con l'r^2 maggiore. |
|
|
|
serbring
Utente Junior
486 Messaggi |
Inserito il - 26 luglio 2009 : 12:54:59
|
ultimo problema e poi tutto mi dovrebbe tornare e per un po' R lo pensioner�....:)
vorrei usare il comando predict per trovare i valori del modello di regressione in punti in cui non ho i valori misurati. Solamente che usando il comando in questo modo ottengo errore
prova<-predict(fmspline, data)
dove fmspline � il modello di regressione e data sono i nuovi valori dove calcolare la funzione
R mi dice che Errore in eval(predvars, data, env) : l'argomento di tipo numeric 'envir' non ha lunghezza uno |
|
|
|
chick80
Moderatore
Citt�: Edinburgh
11491 Messaggi |
Inserito il - 28 luglio 2009 : 15:04:10
|
Guarda, non ho mai usato quelle funzioni, ho provato a darci un'occhiata ma non ci ho cavato fuori troppo sorry.
Per� nel frattempo ho trovato questo articolo interessante:
When a good fit can be bad.
PS: se non ti scoccia posteresti un esempio di come fare un fit di una spline (anche con dati fittizi ovviamente), pu� sempre essere utile a qualcuno in futuro! Grazie mille
|
Sei un nuovo arrivato?
Leggi il regolamento del forum e presentati qui
My photo portfolio (now on G+!) |
|
|
|
serbring
Utente Junior
486 Messaggi |
Inserito il - 11 agosto 2009 : 16:32:12
|
Citazione:
Messaggio inserito da chick80
Guarda, non ho mai usato quelle funzioni, ho provato a darci un'occhiata ma non ci ho cavato fuori troppo sorry.
Per� nel frattempo ho trovato questo articolo interessante:
When a good fit can be bad.
PS: se non ti scoccia posteresti un esempio di come fare un fit di una spline (anche con dati fittizi ovviamente), pu� sempre essere utile a qualcuno in futuro! Grazie mille
grazie per l'articolo sembrerebbe molto interessante ed utile in quello che sto facendo.
scusami se ti rispondo solo ora ma ero in vacanza e prima della partenza dovevo correre per consegnare un lavoro.
Alora ecco come fare il fit di una spline che sia lineare fino a 0.25
x <- seq(0,1,length=250)
y <- (x-0.4)^2 + rnorm(250, 0, 0.05)
plot(x,y)
fit <- lm( y ~ rcs(x, c(0.25, 0.5, 0.75) ) )
fit
lines(x, predict(fit, data.frame(x=x)), col='green')
la funzione rcs si trova nel pacchetto Design. Se serve altro a disposizione ;) per una volta tanto posso essere utile a te. :)
|
|
|
|
chick80
Moderatore
Citt�: Edinburgh
11491 Messaggi |
|
|
serbring
Utente Junior
486 Messaggi |
Inserito il - 20 agosto 2009 : 15:16:18
|
Citazione:
Messaggio inserito da chick80
Grazie mille! Appena torno a casa (sono ancora in vacanza!  ) lo provo ) lo provo
finalmente riesco a dirti una cosa su R che te non sapevi ;)
|
|
|
|
chick80
Moderatore
Citt�: Edinburgh
11491 Messaggi |
|
|
serbring
Utente Junior
486 Messaggi |
Inserito il - 26 febbraio 2010 : 13:47:16
|
ritorno ancora con il mio discorso sulla regressione. Dopo aver calcolato la regressione, l'equazione della retta di regressione lo conoscevo, ho visto che la dispersione, in tutti i casi eccetto uno � bassa. Cmq ho scritto poi l'articolo presentando le curve di regressione con i punti. Il revisore mi ha detto chiesto di sviluppare la statistica dietro a quella tecnica di regressione. Nello specifico cosa vuole che gli mostro? R^2, Gli devo mostrare i vari grafici dei residui? Preciso che il mio articolo � di tipo pi� che altro sperimentale e che il fine non � quello di verificare se i valori rispecchiano in qualche modo la teoria, ma volevo solo vedere se si poteva fare quella cosa in un certo modo. Ho usato quella formula per mostrare il trend dei miei dati seguono un certo trend attraverso un buon fit. Neanche ho mostrato l'equazione della curva perch� non la ritenevo utile per il fine della pubblicazione; ho solo preso un coefficiente della formula e l'ho mostrato essendo fisicamente utile.
Preciso inoltre, che lui non ha assolutamente idea di quello che sto parlando in quanto il modello si chiama magic formula e lui me l'ha commentata scrivendomi: if this formula is magic, this is the wrong journal . :D Questa formula � incredibilmente famosa ed importante da avere addirittura una pagina su wikipedia. |
|
|
| |
Discussione |
|



