| Autore |
Discussione |
|
|
chick80
Moderatore


Citt�: Edinburgh

11491 Messaggi |
 Inserito il - 12 novembre 2010 : 09:43:26 Inserito il - 12 novembre 2010 : 09:43:26




|
Perch� non provi a inserire qui sul forum un file con i dati?
Per allegare file devi usare il link "Rispondi" (e non la "risposta veloce"), avrai un'opzione "allega file". |
Sei un nuovo arrivato?
Leggi il regolamento del forum e presentati qui
My photo portfolio (now on G+!) |
 |
|
|
TMax
Utente Junior


Prov.: BG
Citt�: Capriate
270 Messaggi |
Inserito il - 12 novembre 2010 : 10:17:16
|
concordo...
è più facile capire |
|
|
|
kristanko
Utente Junior
Citt�: Bologna
123 Messaggi |
|
|
chick80
Moderatore
Citt�: Edinburgh
11491 Messaggi |
Inserito il - 12 novembre 2010 : 11:03:18
|
No, no, proprio i valori delle conte.
In questo modo possiamo guardarli un po' anche con altri software con nei quali "ci muoviamo" meglio (es. io uso R). |
Sei un nuovo arrivato?
Leggi il regolamento del forum e presentati qui
My photo portfolio (now on G+!) |
|
|
|
TMax
Utente Junior
Prov.: BG
Citt�: Capriate
270 Messaggi |
 Inserito il - 12 novembre 2010 : 11:04:35 Inserito il - 12 novembre 2010 : 11:04:35
|
no ... 
dovresti postare il dataset
i tuoi dati quelli che hai dato in pasto a graphpad
quelli che probabilmente hai messo in excel
i dati crudi! |
|
|
|
kristanko
Utente Junior
Citt�: Bologna
123 Messaggi |
Inserito il - 12 novembre 2010 : 11:42:11
|
ah ok!!
per� poi mi spiegate che cosa si fa eh?
Allegato:  Cartel1.xls Cartel1.xls
19,16 KB |
|
|
|
TMax
Utente Junior
Prov.: BG
Citt�: Capriate
270 Messaggi |
Inserito il - 12 novembre 2010 : 12:15:42
|
cosi i dati non si possono analizzare
devi ricostruire il dataset facendo in modo che sia chiaro quali sono i fattori sperimentali e quelli da controllare
cercando d'interpetare i tuoi dati mi pare di capire che un tracciato per un dataset corretto
dovrebbe essere fatto cosi
piastra trattamento tempo conta
� un tipico dataset longitudinale
prova a compilare il dataset come impostato su ....
sempre che ho capito
 |
|
|
|
TMax
Utente Junior
Prov.: BG
Citt�: Capriate
270 Messaggi |
Inserito il - 12 novembre 2010 : 12:26:48
|
una roba del genere
ho provato ad inserire i dati sulla base di quello che ho capito dal tuo file
Allegato: prova.xls
25,83 KB |
|
|
|
kristanko
Utente Junior
Citt�: Bologna
123 Messaggi |
Inserito il - 12 novembre 2010 : 12:41:22
|
ahh ok ok... si hai ragione, ho inserito il file senza renderlo chiaro!! Solo niente "piastre". Perch� semplicemente � UNA per ogni CAMPIONE. Scusami ho proprio toppato!! Ri-inserisco i dati con i valori gi� convertiti direttamente in "numero di cellule" divisi nei 3 tempi e per le tre concentrazioni! dimmi se � pi� chiaro!
Allegato: Cartel1.xls
20,19 KB |
|
|
|
chick80
Moderatore
Citt�: Edinburgh
11491 Messaggi |
Inserito il - 12 novembre 2010 : 12:43:56
|
Ok, scusa, avevo scritto una risposta guardando i vecchi dati e ora la cosa non mi torna pi�.
Ho qualche domanda prima di riscrivere una risposta: il primo punto � a 24 ore. Hai delle conte a tempo 0? Sei sicuro che ci fosse lo stesso numero di cellule nelle piastre controllo e in quelle trattate? Il trattamento � stato fatto a t=0 o a t=24h? |
Sei un nuovo arrivato?
Leggi il regolamento del forum e presentati qui
My photo portfolio (now on G+!) |
|
|
|
kristanko
Utente Junior
Citt�: Bologna
123 Messaggi |
Inserito il - 12 novembre 2010 : 13:09:13
|
ricapitolo!
piastro le cellule.
A ventiquattro ore dalla piastratura considero il tempo zero. Faccio a questo punto (t0) delle conte per verificare quale sia il numero iniziale di cellule (che presumo pi� o meno uguale per tutti) e che se pu� interessare � circa 50000.
Quindi a t0 avviene solo il trattamento e una conta di verifica.
Quelle riportate sono le conte a t24, t48 e t72 DAL TRATTAMENTO!
GRAZIE A TUTTI ANCHE PER LA PAZIENZA!!! |
|
|
|
chick80
Moderatore
Citt�: Edinburgh
11491 Messaggi |
Inserito il - 12 novembre 2010 : 13:22:20
|
E' proprio quel "che presumo pi� o meno uguale per tutti" che non � corretto secondo me.
Dovresti secondo me esprimere tutto in % della media delle conte a tempo 0 per ogni gruppo.
Ad ogni modo, sono un po' di fretta ora per fare l'analisi statistica (e cos� la lascio a TMax... ), ci ripasso pi� tardi.
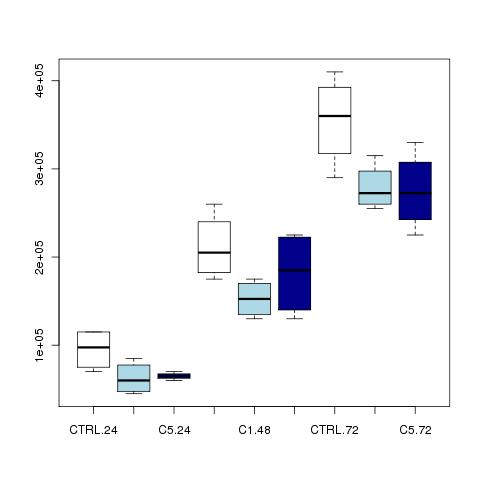
Intanto ecco un grafico che in effetti sembrerebbe indicare una diminuzione della crescita.
La cosa � che sarebbe molto utile aggiungerci le conte a t=0 altrimenti io vedendo questi dati ti posso dire che semplicemente c'erano meno cellule nei trattati...
Immagine:
16,01 KB |
Sei un nuovo arrivato?
Leggi il regolamento del forum e presentati qui
My photo portfolio (now on G+!) |
|
|
|
TMax
Utente Junior
Prov.: BG
Citt�: Capriate
270 Messaggi |
Inserito il - 12 novembre 2010 : 13:30:37
|
miiiiiiiiii che veloce
...guarda un p� se il dataset � giusto?
� importante che si capisca anche il modo corretto per preparare i dati per l'analisi
Allegato: prova.xls
16,11 KB |
|
|
|
chick80
Moderatore
Citt�: Edinburgh
11491 Messaggi |
|
|
TMax
Utente Junior
Prov.: BG
Citt�: Capriate
270 Messaggi |
Inserito il - 12 novembre 2010 : 13:45:27
|
si si la chiamata � una ...
ma io stavo mangiando :-)
|
|
|
|
kristanko
Utente Junior
Citt�: Bologna
123 Messaggi |
Inserito il - 12 novembre 2010 : 13:55:14
|
T-max, si ok... non capisco l'importanza della "piastra" per�!
Chick fenomeno!!! Arriver� al tuo grado di praticit�? Sperem!!
Per Il discorso della conta a T0 � che non avendo ancora trattato le cellule non c'� differenza fra le varie fiasche e quindi tutte e tre le linee (CNTR, T1 e T2) dovrebbero riferirsi allo stesso valore iniziale. Sarebbe come dividere tutti i valori per uno stesso valore (per una costante)e le varie differenze fra CONTROLLO contro TRATTATI non varierebbe!
Non credo abbia senso considerare (poi correggetemi voi se sbaglio) diverse conte per delle cellule che non essendo state trattate sono da considerarsi uguali...! No? |
|
|
|
TMax
Utente Junior
Prov.: BG
Citt�: Capriate
270 Messaggi |
Inserito il - 12 novembre 2010 : 14:06:40
|
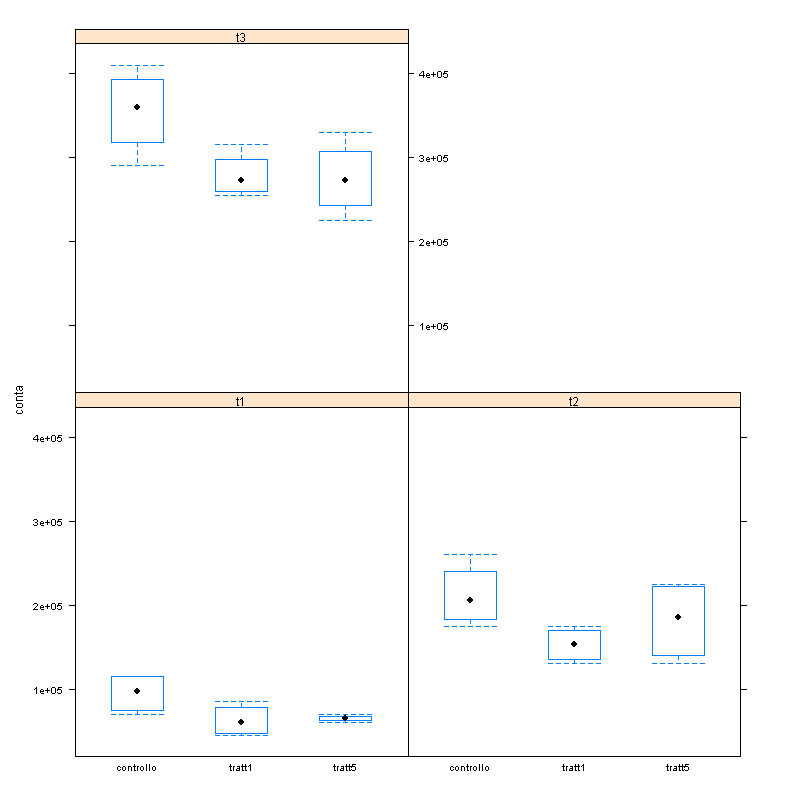
la piastra � imoportante perch� in ambito di disegno sperimentale � un fattore di blocco
e le misure sono ripetute nel tempo nella stessa piastra...
cosi forse si colgono meglio le differenze...
Immagine:
6,54 KB
|
|
|
|
chick80
Moderatore
Citt�: Edinburgh
11491 Messaggi |
Inserito il - 12 novembre 2010 : 14:08:54
|
La piastra pu� essere un effetto confondente. Immagina che una delle piastre fosse in un punto dell'incubatore che prendeva meno CO2, oppure che avesse il fondo non uniforme e le cellule non fossero ben adese etc.
In questo caso non sembrerebbe avere troppa importanza includerlo perch� non c'� differenza fra il fattore "piastra" ed il fattore "trattamento", ma nel momento in cui rifarai l'esperimento e avrai pi� piastre per lo stesso trattamento diventer� importante averlo. |
Sei un nuovo arrivato?
Leggi il regolamento del forum e presentati qui
My photo portfolio (now on G+!) |
|
|
|
kristanko
Utente Junior
Citt�: Bologna
123 Messaggi |
Inserito il - 12 novembre 2010 : 14:13:57
|
Molto bello davvero... Siete dai grandi!
Invece per il discorso della statistica? Qual � il test pi� indicativo? Per avere il famoso "P value < 0.05" ammesso che ci sia... Da quello che ho fatto io (Anova a 2 vie) sembra che "le differenze fra le curve siano significative" e che la differenza fra controllo e trattati � pi� significativa sopratutto a t3.
Puoi venirmi incontro? |
|
|
|
TMax
Utente Junior
Prov.: BG
Citt�: Capriate
270 Messaggi |
Inserito il - 12 novembre 2010 : 14:35:21
|
porta pazienza.....
appena mi libero ti dico |
|
|
|
TMax
Utente Junior
Prov.: BG
Citt�: Capriate
270 Messaggi |
Inserito il - 12 novembre 2010 : 16:42:18
|
| le piastre saranno un problema!!! |
|
|
|
chick80
Moderatore
Citt�: Edinburgh
11491 Messaggi |
Inserito il - 12 novembre 2010 : 23:51:49
|
Allora, ho pensato come analizzare i dati, ma perch� tu possa capirlo devo spiegarti un po' come ho pensato di approcciare il problema. Prima di prendere questo come oro colato, tuttavia, aspetta la conferma di TMax o Glubus o chiunque altro che possa trovare tutti gli errori nella mia spiegazione!!! 
==== Teoria ====
Allora, questo genere di problemi si pu�, come hai gi� letto, risolvere utilizzando un "modello lineare". Cercher� innanzitutto di spiegarti cosa diavolo sarebbe questa cosa (spiegazioni liberamente prese ed adattate da Wikipedia).
In sostanza in statistica un modello � una serie di equazioni (una o pi� di una) che descrivono la relazione delle variabili in una serie di dati.
In questo caso, ad esempio, vogliamo identificare una possibile relazione fra il numero di cellule, il tempo e il trattamento applicato. Avremo quindi una variabile dipendente (il numero di cellule) e dei fattori (il tempo, il trattamento). Ovviamente il tempo ed il trattamento non sono gli unici fattori che influenzano il numero di cellule, in quanto ci sono altri fattori, detti fattori di disturbo (nuisance factor) che sono fattori, come ad es. la piastra, che non interessano lo sperimentatore. TMax giustamente parlava di "fattori di blocco" (blocking factors) perch� in questo tipo di analisi si mettono i dati in "blocchi" definiti dai fattori di interesse.
Ad es. se abbiamo 3 piastre controllo e 3 piastre trattate, creiamo 2 "blocchi": controlli e trattati. Nell'analisi, tuttavia, teniamo conto che in ciascun blocco c'� un fattore di disturbo (la piastra).
Ma quindi come si definisce un modello? Il modello pi� semplice � il modello lineare, che si pu� definire come:

Aspetta!!! Dai, non chiudere il browser!!! ora ti spiego 
- Le varie Yi sono le nostre variabili dipendenti (es. il numero di cellule). Abbiamo un numero di misurazioni n, quindi i va da 1 a n
- X1, X2, ... XP sono i nostri fattori, ad es. il trattamento, che sono anche detti "regressori"
- β0, β1, ... βP sono dei coefficienti che indicano quanto ciascuno di questi fattori � importante nel definire Y
- Φ0, Φ1, ... ΦP sono delle funzioni che possono essere lineari o non lineari (es. dei logaritmi)
Se quindi misuriamo il numero di cellule al passare del tempo potremmo scrivere
numero di cellule = β0 + β1 * Φ1 * trattamento
(in questo la variabile trattamento sar� considerata come un fattore a diversi livelli es. "1", "2", "3" etc. corrispondenti a "controllo", "trattamento 1", "trattamento 2" etc.)
Il modello viene risolto trovando i β che minimizzano la somma:

Nota che ovviamente a te non interessa saper fare tutti questi calcoli (il software di statistica � stato creato apposta), ti sto scrivendo queste cose giusto per darti un'idea generale della situazione.
Ora, in una situazione in cui contiamo il numero di cellule a seconda del trattamento, volendo vedere se il trattamento influenza il numero di cellule potremmo usare un test chiamato ANOVA (analysis of variance) che � essenzialmente un "caso speciale" di modello lineare. Esistono vari tipi di ANOVA, in quel caso useremmo un "ANOVA a una via", in quanto stiamo considerando un solo fattore. L'avevo spiegato (spero correttamente  ) qui: http://www.molecularlab.it/forum/topic.asp?TOPIC_ID=1955 ) qui: http://www.molecularlab.it/forum/topic.asp?TOPIC_ID=1955
Il problema che abbiamo qui � un po' diverso perch� stiamo misurando lo stesso individuo (o la stessa piastra in questo caso) pi� volte (a 3 tempi). In questo caso bisogna usare un "modello lineare gerarchico". Che vuol dire? Vuol dire che hai una gerarchia nei fattori. Ovvero il nostro fattore trattamento diventa un "sottofattore" del tempo, in quanto ad ogni istante di tempo hai diversi trattamenti.
Insomma:
24 ore 48 ore 72 ore
| | |
----------- ------------ ------------
| | | | | | | | |
ctrl T1 T2 ctrl T1 T2 ctrl T1 T2
Un altro esempio potrebbe essere quello di considerare ad es. la produttivit� di diversi operai in diversi dipartimenti di diverse aziende.
C'� un'ultima cosa da introdurre: i regressori del nostro modello possono essere considerati degli "effetti fissi" (in quel caso avremo un fixed effects model) o degli "effetti casuali" (che ci danno un random effect model). Li possiamo anche considerare entrambi, e quindi avere un modello ad effetti misti (mixed effect model). In pratica ad es., misurando un certo parametro in pi� individui, puoi considerare che essi siano tutti uguali (o tutti "ortogonali" rispetto a quel regressore) oppure che ci siano innate differenze tra gli individui che possono influenzare l'output che tu misuri. Nel primo caso il regressore � un effetto fisso, nel secondo un effetto casuale.
=========
Wow, che poema che ho scritto! Questa discussione ce la teniamo cara! :)
Ok, dirai tu, ma come cippa faccio a fare questa cosa in GraphPad? Non ne ho la pi� pallida idea perch� non ce l'ho! :) Tuttavia immagino che avr� qualche funzione del tipo ANOVA a misure ripetute... Ora sono un attimo stremato da tutta questa spiegazione, domani provo a fare i calcoli con R e vediamo che ne esce.
Intanto gentilmente qualcun altro pu� dare una lettura e fare correzioni/puntualizzazioni etc. su quello che ho scritto?
|
Sei un nuovo arrivato?
Leggi il regolamento del forum e presentati qui
My photo portfolio (now on G+!) |
|
|
|
Glubus
Utente Junior

156 Messaggi |
Inserito il - 13 novembre 2010 : 08:02:54
|
perfetto!
in realt� qui il fattore piastra � "confuso" col trattamento per cui, se possiamo ignorarlo (assumendo che vi sia omogeneit� fra le piastre), il tutto si riduce ad un semplice disegno fattoriale.
In fretta due considerazioni: � necessario considerare la deviazione dall'additivit� e cio� l'interazione tempo*trattamento, che � il tuo vero interesse (considera che al tempo 0 tutte le piastre sono nella stessa condizione). L'altra � che, come atteso in dati costituiti da conteggi, la varianza sembra aumentare col livello. Se non si usa qualche cautela (una trasformazione ad esempio) si va incontro ad una violazione dell'assunto della omogeneit� dei residui fra gruppi.
Pi� tardi se ho tempo provo magari ad analizzare i dati.
GB
Citazione:
Messaggio inserito da chick80
Allora, ho pensato come analizzare i dati, ma perch� tu possa capirlo devo spiegarti un po' come ho pensato di approcciare il problema. Prima di prendere questo come oro colato, tuttavia, aspetta la conferma di TMax o Glubus o chiunque altro che possa trovare tutti gli errori nella mia spiegazione!!!
==== Teoria ====
Allora, questo genere di problemi si pu�, come hai gi� letto, risolvere utilizzando un "modello lineare". Cercher� innanzitutto di spiegarti cosa diavolo sarebbe questa cosa (spiegazioni liberamente prese ed adattate da Wikipedia).
In sostanza in statistica un modello � una serie di equazioni (una o pi� di una) che descrivono la relazione delle variabili in una serie di dati.
In questo caso, ad esempio, vogliamo identificare una possibile relazione fra il numero di cellule, il tempo e il trattamento applicato. Avremo quindi una variabile dipendente (il numero di cellule) e dei fattori (il tempo, il trattamento). Ovviamente il tempo ed il trattamento non sono gli unici fattori che influenzano il numero di cellule, in quanto ci sono altri fattori, detti fattori di disturbo (nuisance factor) che sono fattori, come ad es. la piastra, che non interessano lo sperimentatore. TMax giustamente parlava di "fattori di blocco" (blocking factors) perch� in questo tipo di analisi si mettono i dati in "blocchi" definiti dai fattori di interesse.
Ad es. se abbiamo 3 piastre controllo e 3 piastre trattate, creiamo 2 "blocchi": controlli e trattati. Nell'analisi, tuttavia, teniamo conto che in ciascun blocco c'� un fattore di disturbo (la piastra).
Ma quindi come si definisce un modello? Il modello pi� semplice � il modello lineare, che si pu� definire come:
Aspetta!!! Dai, non chiudere il browser!!! ora ti spiego
- Le varie Yi sono le nostre variabili dipendenti (es. il numero di cellule). Abbiamo un numero di misurazioni n, quindi i va da 1 a n
- X1, X2, ... XP sono i nostri fattori, ad es. il trattamento, che sono anche detti "regressori"
- #946;0, #946;1, ... #946;P sono dei coefficienti che indicano quanto ciascuno di questi fattori � importante nel definire Y
- #934;0, #934;1, ... #934;P sono delle funzioni che possono essere lineari o non lineari (es. dei logaritmi)
Se quindi misuriamo il numero di cellule al passare del tempo potremmo scrivere
numero di cellule = #946;0 + #946;1 * #934;1 * trattamento
(in questo la variabile trattamento sar� considerata come un fattore a diversi livelli es. "1", "2", "3" etc. corrispondenti a "controllo", "trattamento 1", "trattamento 2" etc.)
Il modello viene risolto trovando i #946; che minimizzano la somma:
Nota che ovviamente a te non interessa saper fare tutti questi calcoli (il software di statistica � stato creato apposta), ti sto scrivendo queste cose giusto per darti un'idea generale della situazione.
Ora, in una situazione in cui contiamo il numero di cellule a seconda del trattamento, volendo vedere se il trattamento influenza il numero di cellule potremmo usare un test chiamato ANOVA (analysis of variance) che � essenzialmente un "caso speciale" di modello lineare. Esistono vari tipi di ANOVA, in quel caso useremmo un "ANOVA a una via", in quanto stiamo considerando un solo fattore. L'avevo spiegato (spero correttamente ) qui: http://www.molecularlab.it/forum/topic.asp?TOPIC_ID=1955
Il problema che abbiamo qui � un po' diverso perch� stiamo misurando lo stesso individuo (o la stessa piastra in questo caso) pi� volte (a 3 tempi). In questo caso bisogna usare un "modello lineare gerarchico". Che vuol dire? Vuol dire che hai una gerarchia nei fattori. Ovvero il nostro fattore trattamento diventa un "sottofattore" del tempo, in quanto ad ogni istante di tempo hai diversi trattamenti.
Insomma:
24 ore 48 ore 72 ore
| | |
----------- ------------ ------------
| | | | | | | | |
ctrl T1 T2 ctrl T1 T2 ctrl T1 T2
Un altro esempio potrebbe essere quello di considerare ad es. la produttivit� di diversi operai in diversi dipartimenti di diverse aziende.
C'� un'ultima cosa da introdurre: i regressori del nostro modello possono essere considerati degli "effetti fissi" (in quel caso avremo un fixed effects model) o degli "effetti casuali" (che ci danno un random effect model). Li possiamo anche considerare entrambi, e quindi avere un modello ad effetti misti (mixed effect model). In pratica ad es., misurando un certo parametro in pi� individui, puoi considerare che essi siano tutti uguali (o tutti "ortogonali" rispetto a quel regressore) oppure che ci siano innate differenze tra gli individui che possono influenzare l'output che tu misuri. Nel primo caso il regressore � un effetto fisso, nel secondo un effetto casuale.
=========
Wow, che poema che ho scritto! Questa discussione ce la teniamo cara! :)
Ok, dirai tu, ma come cippa faccio a fare questa cosa in GraphPad? Non ne ho la pi� pallida idea perch� non ce l'ho! :) Tuttavia immagino che avr� qualche funzione del tipo ANOVA a misure ripetute... Ora sono un attimo stremato da tutta questa spiegazione, domani provo a fare i calcoli con R e vediamo che ne esce.
Intanto gentilmente qualcun altro pu� dare una lettura e fare correzioni/puntualizzazioni etc. su quello che ho scritto?
|
|
|
|
TMax
Utente Junior
Prov.: BG
Citt�: Capriate
270 Messaggi |
Inserito il - 13 novembre 2010 : 09:12:08
|
la spiegazione di chick � magistrale!
si si questa la teniamo...
per� rimanendo nel pratico
abbiamo bisogno di sapere una cosa importantissima che in realt� io non ho capito
e cio�....
le piastra sono letta in 3 tempi diversi?
si tratta sempre della stessa piastra che letta a to , viene riposta e poi riletta a t1 e cosi via?
oppure la lettura prevede in qualche modo la distruzione delle cellule e quindi nei tempi successivi sar� un altra piastra ad essere letta?
qui � importante questa differenza, perch� nel primo caso sar� assolutamente impossibile separare l'effetto piastra da quello del trattamento e in sostanza l'esperimento � da rifare prevedendo per ogni trattamento almeno due piastre
nel secondo caso invece si possono analizzare i dati come indica Stefano alias Glubs e cio� come disegno fattoriale.
facc� sap�
facc� sogn�!!!
 |
|
|
|
chick80
Moderatore
Citt�: Edinburgh
11491 Messaggi |
Inserito il - 13 novembre 2010 : 10:18:59
|
Ti rispondo io TMax, � il primo caso. Praticamente si prende una piccola aliquota di cellule e si conta quell'aliquota usando una cameretta per conte. Dopodich� quelle cellule si buttano via (ovviamente il numero di cellule che prendi � trascurabile rispetto al totale).
Comunque, se ci scordiamo un attimo della piastra, ecco quello che si pu� fare in R. kristanko, se non sai usare R (che puoi scaricare gratuitamente da www.r-project.org ) il codice ti sembrer� abbastanza incomprensibile. Ho cercato di commentarlo il pi� possibile.
Allego il file csv con i dati riorganizzati (c'� dentro anche la piastra ma non la uso nei calcoli qui sotto).
# Leggiamo il file csv
counts <- read.table("conte.csv", header=TRUE, sep=",")
# Riordiniamo i livelli della colonna gruppo e marchiamo la piastra come fattore
counts$Gruppo <- factor(counts$Gruppo, levels=c("CTRL", "C1", "C5"))
# Ora possiamo chiamare la funzione aov che effettua un'analisi della varianza su di un modello lineare.
#Questo � equivalente a generare un modello lineare con la funzione lm e poi lanciare la funzione anova sul risultato.
# La formula Cellule ~ Gruppo * Tempo sta ad indicare che vogliamo vedere la variazione
# di cellule in relazione al Gruppo ed al tempo. Usiamo il '*' tra i due fattori perch�
# ci interessa l'interazione fra i due; in caso contrario avremmo usato +.
counts.aov <- aov(Cellule ~ Gruppo * Tempo, data = counts)
# Scriviamo il risultato
print(summary(counts.aov))
Otteniamo come risultato
Df Sum Sq Mean Sq F value Pr(>F)
Gruppo 2 2.1517e+10 1.0758e+10 9.3834 0.0008053 ***
Tempo 2 3.1434e+11 1.5717e+11 137.0824 7.237e-15 ***
Gruppo:Tempo 4 4.3083e+09 1.0771e+09 0.9394 0.4562086
Residuals 27 3.0956e+10 1.1465e+09
---
Signif. codes: 0 �***� 0.001 �**� 0.01 �*� 0.05 �.� 0.1 � � 1
La tabella ci d� diverse informazioni come i gradi di libert� (Df), la somma dei quadrati dei residui (Sum Sq) la statistica F e il tanto desiderato p-value!
Come vedi c'� sia un effetto del tempo che del trattamento ma non un effetto "incrociato" dei due fattori.
Volendo per� vedere quali tempi e quali gruppi sono diversi fra di loro, dobbiamo fare un test post-hoc, in cui confrontiamo tutte le misurazioni fra loro.
Lanciamo
# Scriviamo l'output del test di Tukey
print(TukeyHSD(counts.aov))
Che ci d�
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = Cellule ~ Gruppo * Tempo, data = counts)
$Gruppo
diff lwr upr p adj
C1-CTRL -55833.333 -90107.46 -21559.21 0.0011264
C5-CTRL -46666.667 -80940.79 -12392.54 0.0061491
C5-C1 9166.667 -25107.46 43440.79 0.7865850
$Tempo
diff lwr upr p adj
48h-24h 107500 73225.88 141774.1 1e-07
72h-24h 228750 194475.88 263024.1 0e+00
72h-48h 121250 86975.88 155524.1 0e+00
$`Gruppo:Tempo`
diff lwr upr p adj
C1:24h-CTRL:24h -32500 -113060.708 48060.7078 0.9038497
C5:24h-CTRL:24h -30000 -110560.708 50560.7078 0.9363135
CTRL:48h-CTRL:24h 116250 35689.292 196810.7078 0.0012823
C1:48h-CTRL:24h 57500 -23060.708 138060.7078 0.3227981
[output tagliato]
Come vedi sia C1 che C5 sono diversi (p<0.05) dai controlli, ma non fra di loro. I tre tempi sono tutti diversi fra loro (non una grande sorpresa qui).
Ho tagliato l'output dei confronti incrociati perch� non dava informazioni ulteriori (avevamo gi� visto dalla chiamata ad AOV che non c'erano interazioni significative).
Se guardi giusto l'inizio, infatti, sono diversi fra loro solo i casi in cui uno dei fattori � fisso e l'altro varia, ma non situazioni in cui i 2 fattori sono diversi in entrambi i termini.
======
E se volessimo considerare le piastre? R ci permette di fare un modello ad effetti misti.
Il problema qui � che credo ci sia un artefatto dovuto al fatto che il fattore Piastre � uguale al fattore Gruppo e quindi anova non riesce a calcolarmi un p-value per il fattore Gruppo.
Se bariamo e facciamo finta che i 4 replicati vengano da 2 piastre diverse allora il tutto funziona ed otteniamo un output simile a quello di cui sopra (se qualcuno fosse interessato posso postare il codice).
OVVIAMENTE QUESTO LO FACCIO SOLO PER SCOPO DIMOSTRATIVO. SE VUOI CONSIDERARE L'EFFETTO DELLA PIASTRA DEVI RIFARE L'ESPERIMENTO CON ALTRE PIASTRE, COME HA DETTO TMax.
GRUPPI
Estimate Std. Error z value Pr(>|z|)
C1 - CTRL == 0 -55833 18742 -2.979 0.00812 **
C5 - CTRL == 0 -46667 18742 -2.490 0.03416 *
C5 - C1 == 0 9167 18742 0.489 0.87650
TEMPI
Linear Hypotheses:
Estimate Std. Error z value Pr(>|z|)
48h - 24h == 0 107500 13125 8.190 <1e-10 ***
72h - 24h == 0 228750 13125 17.428 <1e-10 ***
72h - 48h == 0 121250 13125 9.238 <1e-10 ***
Allegato: conte.csv.zip
1,16�KB |
Sei un nuovo arrivato?
Leggi il regolamento del forum e presentati qui
My photo portfolio (now on G+!) |
|
|
|
Discussione |
|



